pocoMC is a Python implementation of the Preconditioned Monte Carlo method for accelerated Bayesian inference
Getting started
Brief introduction
pocoMC is a Python package for fast Bayesian posterior and model evidence estimation. It leverages
the Preconditioned Monte Carlo (PMC) algorithm, offering significant speed improvements over
traditional methods like MCMC and Nested Sampling. Ideal for large-scale scientific problems
with expensive likelihood evaluations, non-linear correlations, and multimodality, pocoMC
provides efficient and scalable posterior sampling and model evidence estimation. Widely used
in cosmology and astronomy, pocoMC is user-friendly, flexible, and actively maintained.
Documentation
Read the docs at pocomc.readthedocs.io for more information, examples and tutorials.
Installation
To install pocomc using pip run:
pip install pocomc
or, to install from source:
git clone https://github.com/minaskar/pocomc.git
cd pocomc
python setup.py install
Basic example
For instance, if you wanted to draw samples from a 10-dimensional Rosenbrock distribution with a uniform prior, you would do something like:
importpocomcaspcimportnumpyasnpfromscipy.statsimportuniformn_dim=10# Number of dimensionsprior=pc.Prior(n_dim*[uniform(-10.0, 20.0)]) # U(-10,10)deflog_likelihood(x):
return-np.sum(10.0*(x[:,::2]**2.0-x[:,1::2])**2.0 \
+ (x[:,::2] -1.0)**2.0, axis=1)
sampler=pc.Sampler(
prior=prior,
likelihood=log_likelihood,
vectorize=True,
)
sampler.run()
samples, weights, logl, logp=sampler.posterior() # Weighted posterior sampleslogz, logz_err=sampler.evidence() # Bayesian model evidence estimate and uncertainty
Attribution & Citation
Please cite the following papers if you found this code useful in your research:
@article{karamanis2022accelerating,
title={Accelerating astronomical and cosmological inference with preconditioned Monte Carlo},
author={Karamanis, Minas and Beutler, Florian and Peacock, John A and Nabergoj, David and Seljak, Uro{\v{s}}},
journal={Monthly Notices of the Royal Astronomical Society},
volume={516},
number={2},
pages={1644--1653},
year={2022},
publisher={Oxford University Press}
}
@article{karamanis2022pocomc,
title={pocoMC: A Python package foraccelerated Bayesian inferencein astronomy and cosmology},
author={Karamanis, Minas and Nabergoj, David and Beutler, Florian and Peacock, John A and Seljak, Uros},
journal={arXiv preprint arXiv:2207.05660},
year={2022}
}
Licence
Copyright 2022-Now Minas Karamanis and contributors.
pocoMC is free software made available under the GPL-3.0 License. For details see the LICENSE file.
pocoMC is a Python implementation of the Preconditioned Monte Carlo method for accelerated Bayesian inference
Getting started
Brief introduction
pocoMC is a Python package for fast Bayesian posterior and model evidence estimation. It leverages
the Preconditioned Monte Carlo (PMC) algorithm, offering significant speed improvements over
traditional methods like MCMC and Nested Sampling. Ideal for large-scale scientific problems
with expensive likelihood evaluations, non-linear correlations, and multimodality, pocoMC
provides efficient and scalable posterior sampling and model evidence estimation. Widely used
in cosmology and astronomy, pocoMC is user-friendly, flexible, and actively maintained.
Documentation
Read the docs at pocomc.readthedocs.io for more information, examples and tutorials.
Installation
To install pocomc using pip run:
pip install pocomc
or, to install from source:
git clone https://github.com/minaskar/pocomc.git
cd pocomc
python setup.py install
Basic example
For instance, if you wanted to draw samples from a 10-dimensional Rosenbrock distribution with a uniform prior, you would do something like:
importpocomcaspcimportnumpyasnpfromscipy.statsimportuniformn_dim=10# Number of dimensionsprior=pc.Prior(n_dim*[uniform(-10.0, 20.0)]) # U(-10,10)deflog_likelihood(x):
return-np.sum(10.0*(x[:,::2]**2.0-x[:,1::2])**2.0 \
+ (x[:,::2] -1.0)**2.0, axis=1)
sampler=pc.Sampler(
prior=prior,
likelihood=log_likelihood,
vectorize=True,
)
sampler.run()
samples, weights, logl, logp=sampler.posterior() # Weighted posterior sampleslogz, logz_err=sampler.evidence() # Bayesian model evidence estimate and uncertainty
Attribution & Citation
Please cite the following papers if you found this code useful in your research:
@article{karamanis2022accelerating,
title={Accelerating astronomical and cosmological inference with preconditioned Monte Carlo},
author={Karamanis, Minas and Beutler, Florian and Peacock, John A and Nabergoj, David and Seljak, Uro{\v{s}}},
journal={Monthly Notices of the Royal Astronomical Society},
volume={516},
number={2},
pages={1644--1653},
year={2022},
publisher={Oxford University Press}
}
@article{karamanis2022pocomc,
title={pocoMC: A Python package foraccelerated Bayesian inferencein astronomy and cosmology},
author={Karamanis, Minas and Nabergoj, David and Beutler, Florian and Peacock, John A and Seljak, Uros},
journal={arXiv preprint arXiv:2207.05660},
year={2022}
}
Licence
Copyright 2022-Now Minas Karamanis and contributors.
pocoMC is free software made available under the GPL-3.0 License. For details see the LICENSE file.
Object by Object – Auf den Spuren der Zwanziger in Berlin ist ein Schnitzeljagd-Spiel für iOS-Geräte, das im öffentlichen Raum mit Hilfe von Persistent Augmented Reality (Persistent AR) gespielt werden kann.
Entstehungskontext
Diese AR-Anwendung ist ein Prototyp, entstanden im Verbundprojekt museum4punkt0 – Digitale Strategien für das Museum der Zukunft, Teilprojekt Zentrale wissenschaftliche Projektsteuerung. Weitere Informationen: www.museum4punkt0.de
Förderhinweis
Das Projekt museum4punkt0 wird gefördert durch die Beauftragte der Bundesregierung für Kultur und Medien aufgrund eines Beschlusses des Deutschen Bundestages.
Update: Um das Eintragen der API-Keys zu vereinfachen, sollten die in der Anleitung beschriebenen Credentials nicht mehr direkt im Code, sondern separat in der Datei
Credits
Auftraggeber: Stiftung Preußischer Kulturbesitz, museum4punkt0
Design und Programmierung: Ekkehard Petzold und Jan Alexander in Zusammenarbeit mit museum4punkt0
Code und Dokumentation in diesem Repositorium wurden begutachtet durch TICE Software UG (haftungsbeschränkt) (https://tice.software/de/)
Lizenz
Copyright (c) 2020 / museum4punkt0, Ekkehard Petzold, Jan Alexander
Die in diesem Repositorium veröffentlichte Anwendung wird unter der MIT Lizenz veröffentlicht. Näheres siehe in der Lizenz-Datei.
Sämtliche verwendete Programmteile Dritter sind nachfolgend aufgeführt und stehen unter der MIT-Lizenz:
Object by Object – Auf den Spuren der Zwanziger in Berlin ist ein Schnitzeljagd-Spiel für iOS-Geräte, das im öffentlichen Raum mit Hilfe von Persistent Augmented Reality (Persistent AR) gespielt werden kann.
Entstehungskontext
Diese AR-Anwendung ist ein Prototyp, entstanden im Verbundprojekt museum4punkt0 – Digitale Strategien für das Museum der Zukunft, Teilprojekt Zentrale wissenschaftliche Projektsteuerung. Weitere Informationen: www.museum4punkt0.de
Förderhinweis
Das Projekt museum4punkt0 wird gefördert durch die Beauftragte der Bundesregierung für Kultur und Medien aufgrund eines Beschlusses des Deutschen Bundestages.
Update: Um das Eintragen der API-Keys zu vereinfachen, sollten die in der Anleitung beschriebenen Credentials nicht mehr direkt im Code, sondern separat in der Datei
Credits
Auftraggeber: Stiftung Preußischer Kulturbesitz, museum4punkt0
Design und Programmierung: Ekkehard Petzold und Jan Alexander in Zusammenarbeit mit museum4punkt0
Code und Dokumentation in diesem Repositorium wurden begutachtet durch TICE Software UG (haftungsbeschränkt) (https://tice.software/de/)
Lizenz
Copyright (c) 2020 / museum4punkt0, Ekkehard Petzold, Jan Alexander
Die in diesem Repositorium veröffentlichte Anwendung wird unter der MIT Lizenz veröffentlicht. Näheres siehe in der Lizenz-Datei.
Sämtliche verwendete Programmteile Dritter sind nachfolgend aufgeführt und stehen unter der MIT-Lizenz:
A fun and addictive browser-based fish eating game inspired by the classic Feeding Frenzy. Eat smaller fish to grow bigger while avoiding larger predators!
🎮 Play Now
Love casual games? Also check out our popular 2048 Game Collection featuring classic number puzzles and exciting variants!
✨ Features
Smooth HTML5 Canvas gameplay
Multiple fish species with unique behaviors
Progressive difficulty scaling
Score tracking and achievements
Mobile-friendly controls
No installation required – play directly in browser
🎯 How to Play
Control your fish using mouse/touch movements
Eat fish smaller than you to grow larger
Avoid bigger fish that can eat you
Reach size goals to progress through levels
Try to achieve the highest score!
🔧 Development
Built with:
HTML5 Canvas
JavaScript
CSS3
🎲 More Games
Love this game? Check out our other popular browser games:
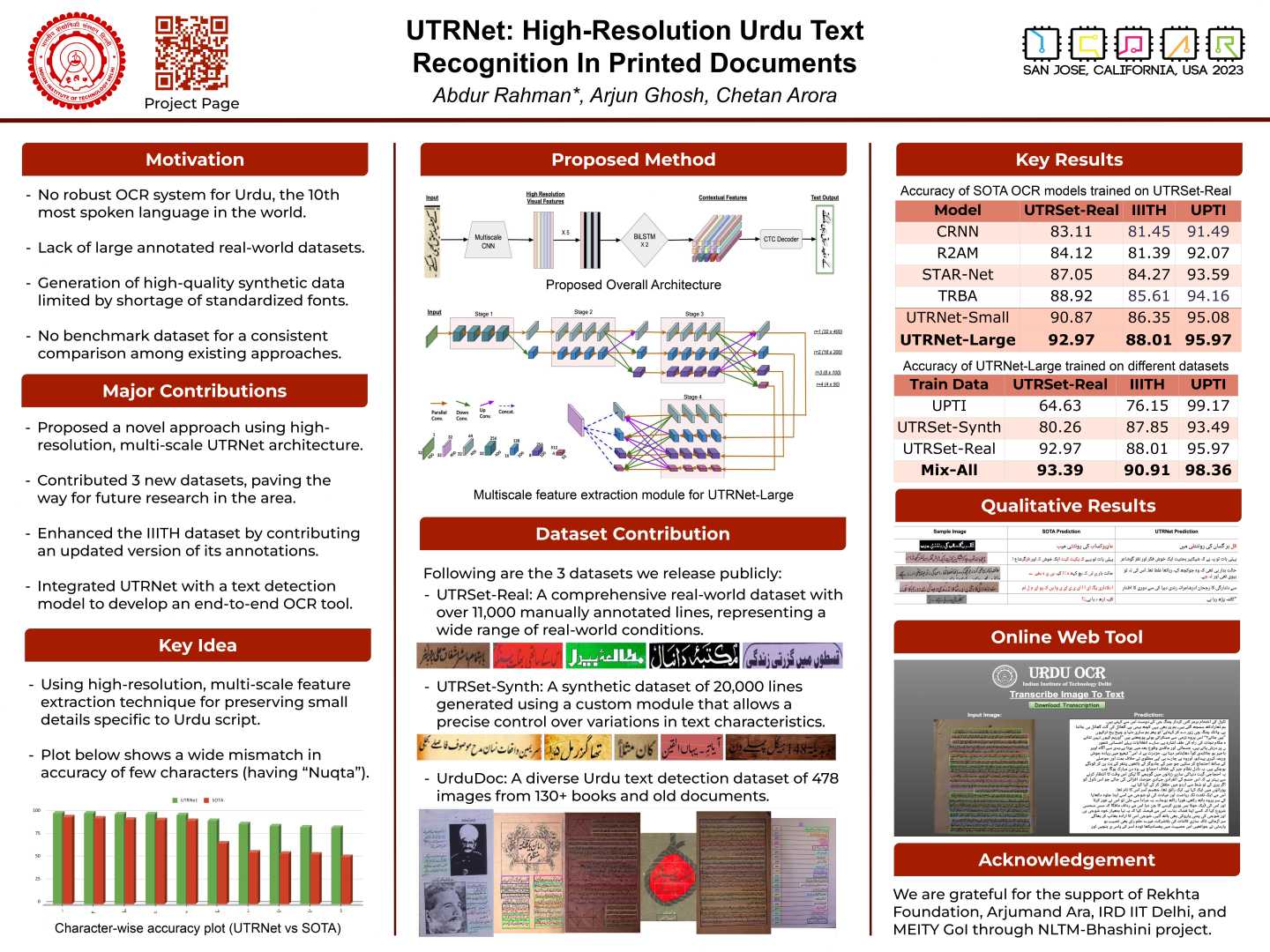
UrduDoc – Will be made available subject to the execution of a no-cost license agreement. Please contact the authors for the same.
Text Detection (Supplementary)
The text detection inference code & model based on ContourNet is here. As mentioned in the paper, it may be integrated with UTRNet for a combined text detection+recognition and hence an end-to-end Urdu OCR.
Synthetic Data Generation using Urdu-Synth (Supplementary)
The UTRSet-Synth dataset was generated using a custom-designed robust synthetic data generation module – Urdu Synth.
The application is deployed on Hugging Face Spaces and is available for a live demo. You can access it here. If you prefer to run it locally, you can clone its repository and follow the instructions given there – Repo.
Note:This version of the application uses a YoloV8 model for text detection. The original version of UTRNet uses ContourNet for this purpose. However, due to deployment issues, we have opted for YoloV8 in this demo. While YoloV8 is as accurate as ContourNet, it offers the advantages of faster processing and greater efficiency.
We acknowledge the Rekhta Foundation and the personal collections of Arjumand Ara for the scanned images and Noor Fatima and Mohammed Usman for the dataset and the manual transcription.
This is an official repository of the project. The copyright of the dataset, code & models belongs to the authors. They are for research purposes only and must not be used for any other purpose without the author’s explicit permission.
Citation
If you use the code/dataset, please cite the following paper:
@InProceedings{10.1007/978-3-031-41734-4_19,
author="Rahman, Abdur and Ghosh, Arjun and Arora, Chetan",
editor="Fink, Gernot A. and Jain, Rajiv and Kise, Koichi and Zanibbi, Richard",
title="UTRNet: High-Resolution Urdu Text Recognition in Printed Documents",
booktitle="Document Analysis and Recognition - ICDAR 2023",
year="2023",
publisher="Springer Nature Switzerland",
address="Cham",
pages="305--324",
isbn="978-3-031-41734-4",
doi="https://doi.org/10.1007/978-3-031-41734-4_19"
}
Translations in languages other than English are machine translated and are not yet accurate. No errors have been fixed yet as of March 21st 2021. Please report translation errors here. Make sure to backup your correction with sources and guide me, as I don’t know languages other than English well (I plan on getting a translator eventually) please cite wiktionary and other sources in your report. Failing to do so will result in a rejection of the correction being published.
Note: due to limitations with GitHub’s interpretation of markdown (and pretty much every other web-based interpretation of markdown) clicking these links will redirect you to a separate file on a separate page that isn’t the intended page. You will be redirected to the .github folder of this project, where the README translations are hosted.
Translations are currently done with Bing translate and DeepL. Support for Google Translate translations is coming to a close due to privacy concerns.
Try it out! The sponsor button is right up next to the watch/unwatch button.
Version history
Version history currently unavailable
No other versions listed
Software status
All of my works are free some restrictions. DRM (Digital Restrictions Management) is not present in any of my works.
This sticker is supported by the Free Software Foundation. I never intend to include DRM in my works.
I am using the abbreviation “Digital Restrictions Management” instead of the more known “Digital Rights Management” as the common way of addressing it is false, there are no rights with DRM. The spelling “Digital Restrictions Management” is more accurate, and is supported by Richard M. Stallman (RMS) and the Free Software Foundation (FSF)
This section is used to raise awareness for the problems with DRM, and also to protest it. DRM is defective by design and is a major threat to all computer users and software freedom.
The controller for the model uses the ArduPilot Lua scripting framework to support the custom frame
and control the 6 wheel motors and 4 steering servos.
This is a Gazebo model of a board with castor wheels powered by a steerable rotor.
This toy model provides an exercise in tuning a vehicle with poor yaw control inspired
by this ArduPilot Discord post by Peter Barker.
License
This is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This software is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
Atenção: a versão 5.0.0+ do bling-erp-api para Javascript/TypeScript
utiliza a API v3 do Bling. Caso deseja utilizar a API v2 do Bling,
utilize a versão 4.0.0.
Instalação
Para instalar, execute o comando:
npm i bling-erp-api
Criação de uma nova conexão
Para criar uma conexão ao serviço do Bling, basta instanciar o objeto com a API key em seu construtor.
Vale destacar que o fluxo de criação e autorização do aplicativo não é feito
pela biblioteca. Ou seja, a biblioteca somente recebe o access_token gerado
a partir do endpoint/token. Veja a referência.
This GitHub repository is dedicated to an NFT standard (TEP-62), which provides a set of guidelines and specifications for creating and managing non-fungible tokens (NFTs) on blockchain platforms.
The repository contains a comprehensive collection of code files, documentation, and resources that developers can utilize to implement the standard in their NFT projects. It offers a well-defined structure and functionality for NFT contracts, including features like token metadata, ownership transfers, and token enumeration.
The repository also includes sample code and examples to help developers understand and implement the NFT standard more easily. Collaborators and contributors actively maintain and update the repository, ensuring it remains up-to-date with the latest advancements and best practices in the NFT ecosystem.
yarn build # To build contract
yarn test# To run test cases
yarn deploy # To deploy contract
yarn read# The way to read the smart contract data after your deployed the code
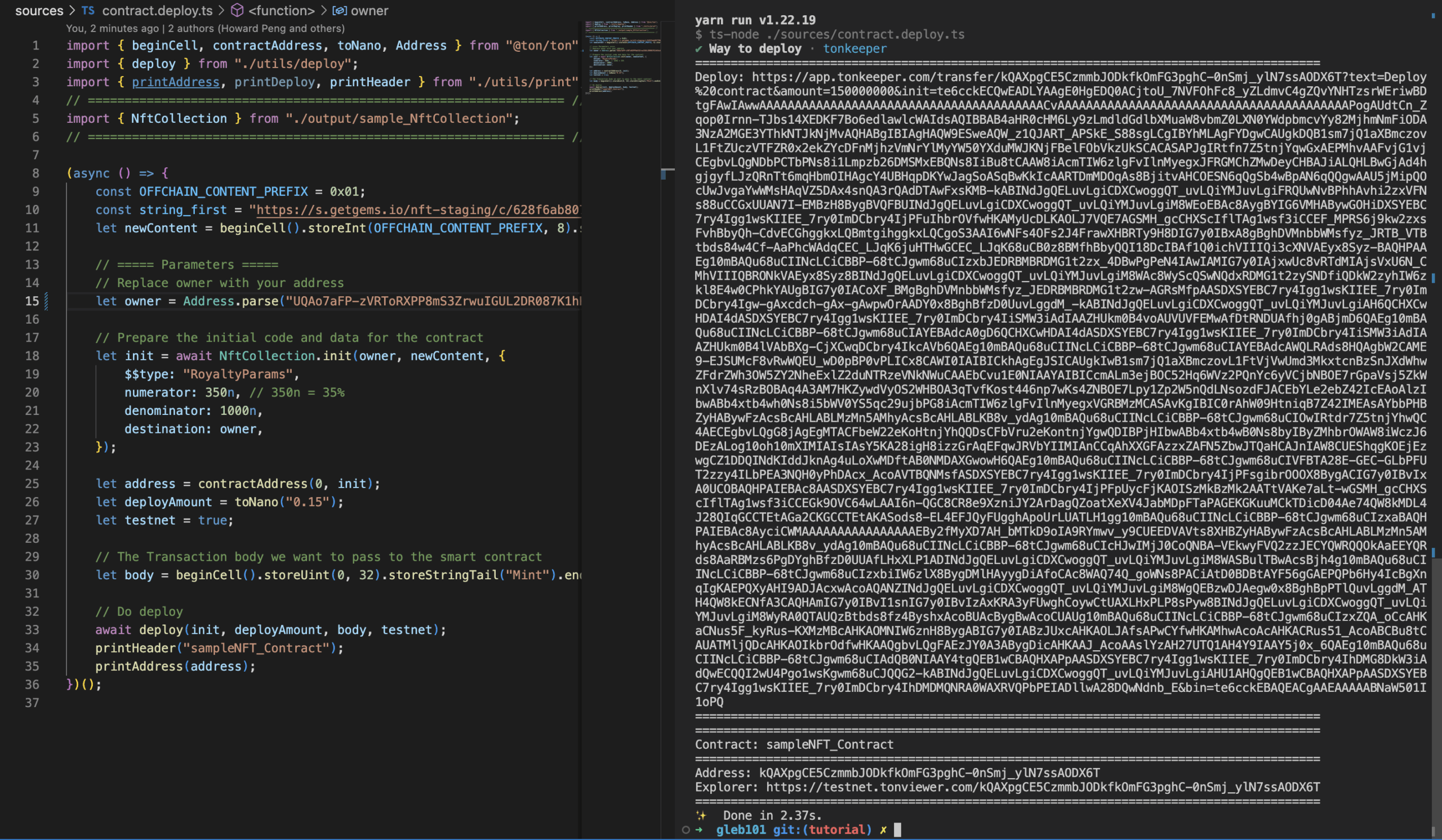
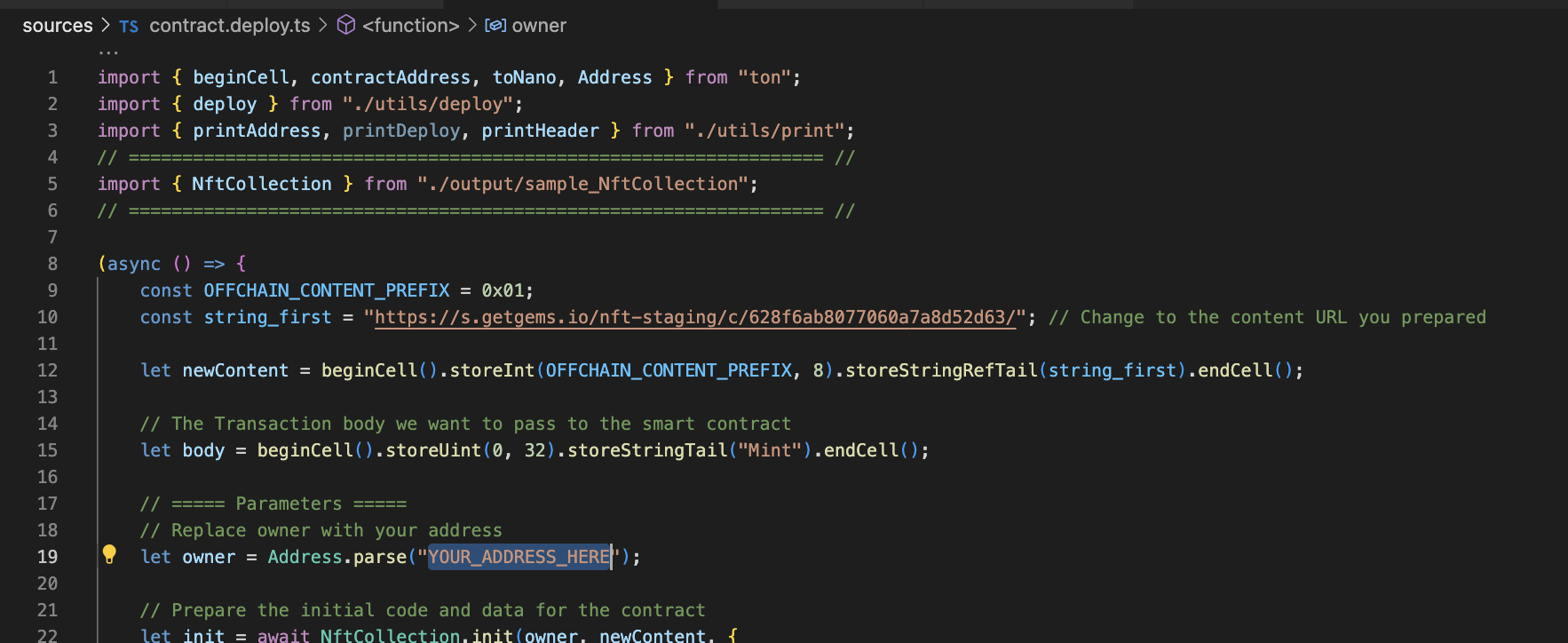
Warning
Remember to change the parameter in contract.deploy.ts file before you run yarn deploy
– once you run yarn deploy you will get the address of the deployed contract. You can use this address to interact with the contract.
More
For more information about this GitHub repository, or if you have any questions related to Tact, feel free to visit:





 https://github.com/minaskar/pocomc
https://github.com/minaskar/pocomc